Facial Activity Intensity
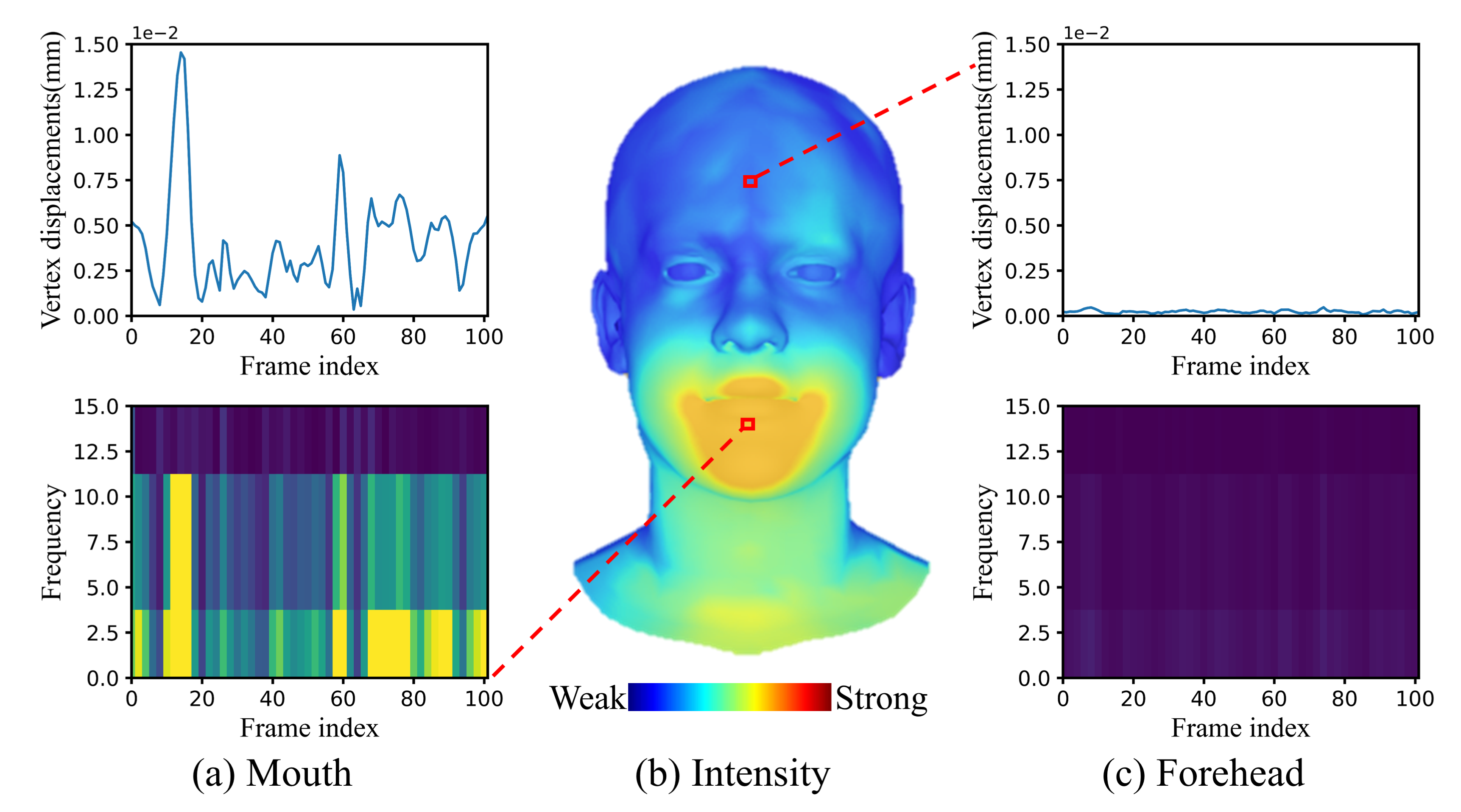

CorrTalk first analyses differences in facial activity intensity cross distinct regions. Facial activity intensity is quantified using amplitude values within the fundamental band of the short-time Fourier transform(STFT). Left: activity intesity of a vertex in mouth and forehead region within a motion sequence are shown in (a) and (c) (top row: \(L_{2}\) distance between vertices in the reference sequence and the neutral topology; bottom row: STFT of the vertex displacements.). (b) represents the average facial activity intensity from the training data. Right: dynamics of facial activity intensity in a sequence.
Method
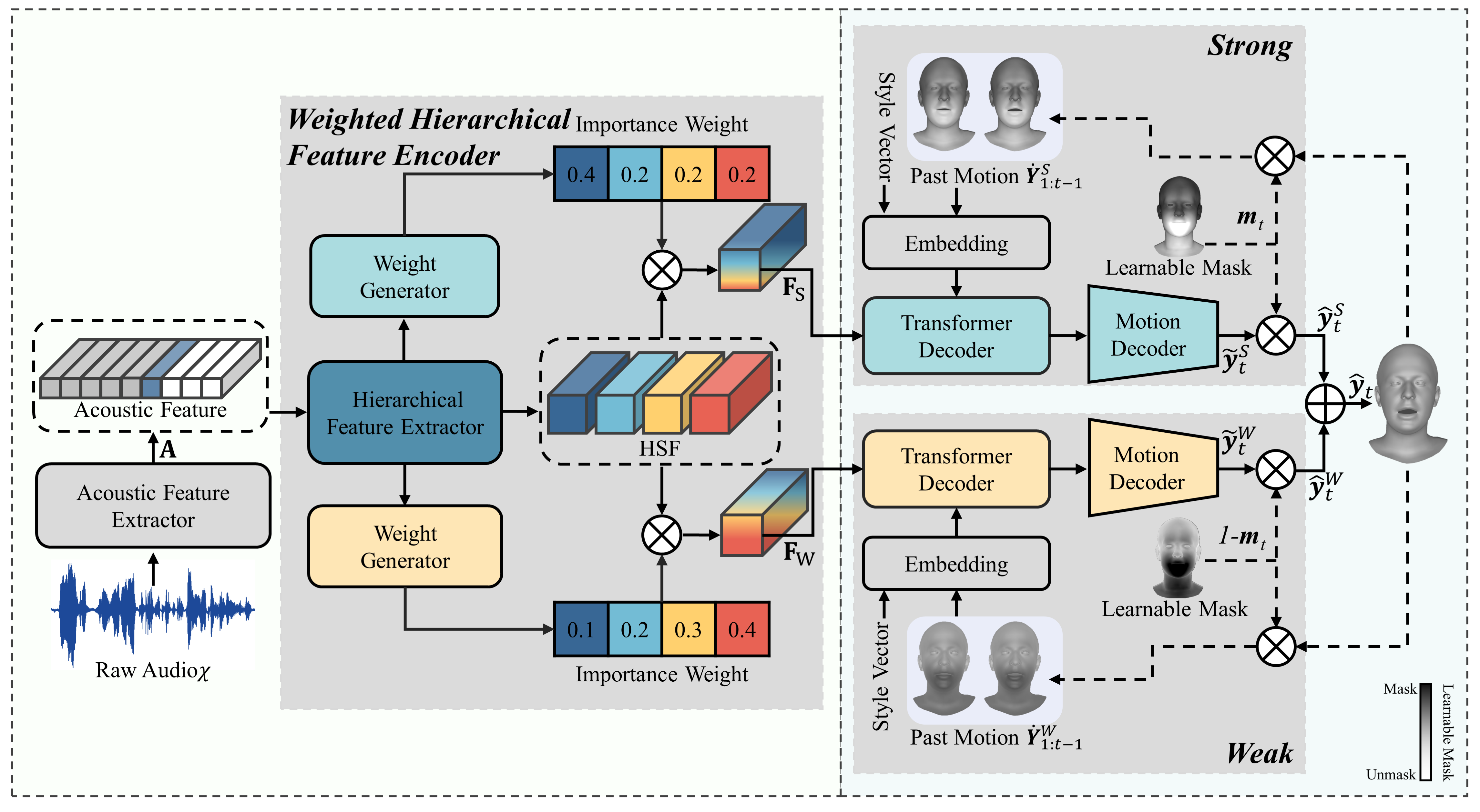
Overview of the proposed CorrTalk. A novel framework for learning the temporal correlation between HSF and facial activities of different intensities uses raw audio as input and generates a sequence of 3D facial animation. The design of the acoustic feature extractor follows wavLM. The weighted hierarchical speech encoder produces frame-, phoneme-, word- and utterance-level speech features, and calculates the importance weight of each level of features for strong and weak facial movements. A dual-branch decoder based on the FAI synchronously generates strong and weak facial movements. After performing STFT of the vertex displacements from training data, a learnable mask \(\mathbf{m}_t \in [0, 1] \) is initialized according to the absolute value of the amplitude in fundamental frequency. \(\mathbf{m}_t (\cdot) \) close to 1 indicates strong facial movements and vice versa for weak movements.
Comparison
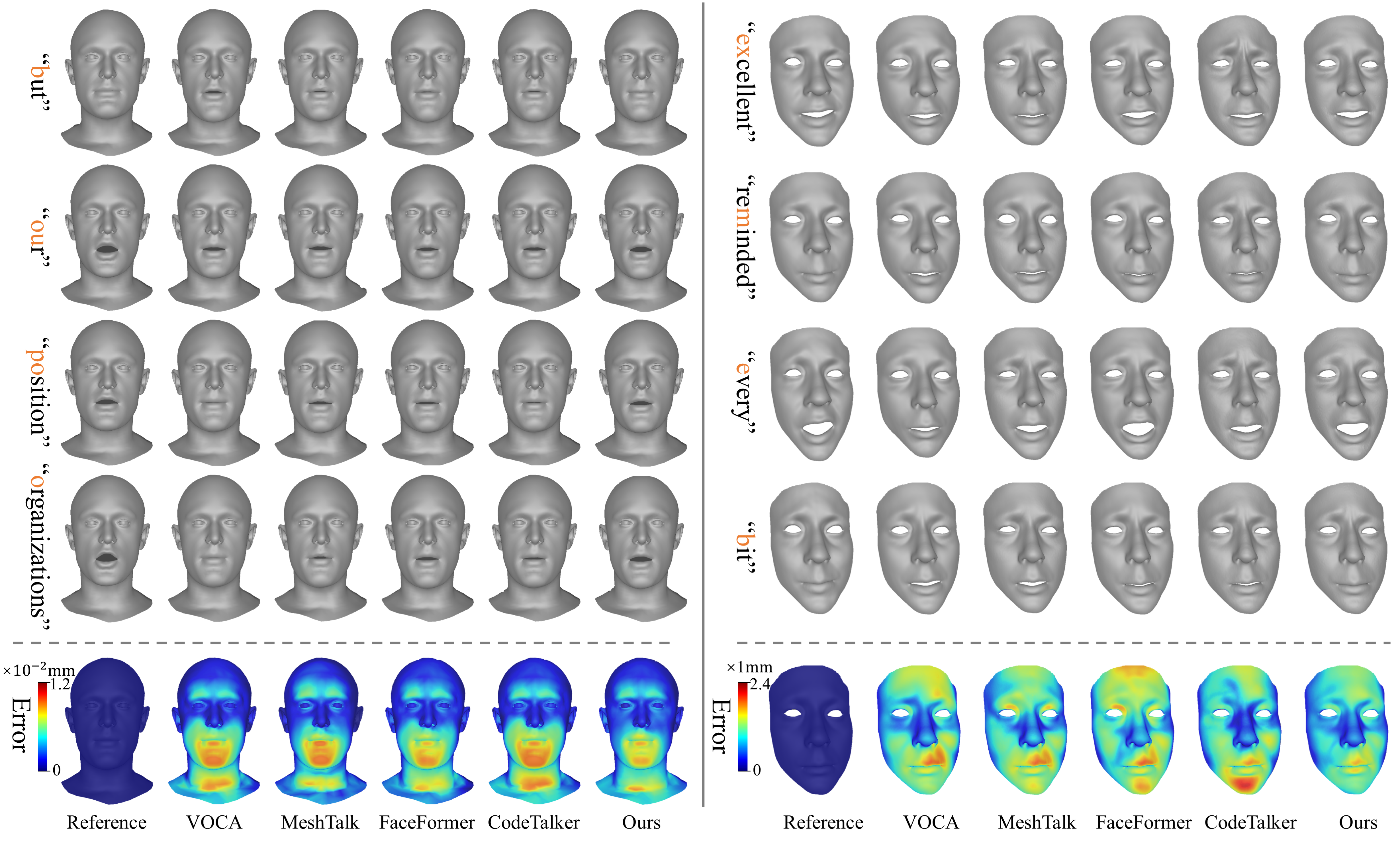
Visual comparison of sampled facial animations generated by different methods on VOCA-Test (left) and BIWI-Test-B (right). The top portion delineates facial animations associated with distinct speech content. The bottom portion displays the synthetic sequence with ground truth mean error.